San Francisco is a renowned metropolis, situated in North California, USA, and serves as the commercial, financial, and cultural center of the region. This has attracted a significant influx of migrants to the city, and as of 2021, it has a population of 815,201 residents up to 2021, who have made a notable contribution to the city’s economy.
However, the city’s diverse socioeconomic challenges have also contributed to a high crime rate.
1.1 Dataset
In this story, we will examine the San Francisco Police Department’s (SFPD) Incient Report Dataset, which covers the period from January 2003 to May 2018.
The dataset contains information on criminal incidents reported in San Francisco, including the incident date, time, category, police district, latitude, longitude, and more. It comprises over 2 million records of crimes, with 35 columns of data.
The dataset reveals that 37 categories of crimes were recorded across the city of San Francisco.
1.2 Abstract
The aim of this report is utilizing the techniques of data visualization for the analytics of crime occured in San Francisco. The primary idea of this data analysis study is to obtain the insights from the observation, in order to evaluate the criminal situation for the past decades in San Francisco, as well as help prevent potential crimes in the future.
The data analysis will be based on Time-Series, Geographic and Interative Visualization respectively.
According to SFNext Index, with the exception of robberies, violent crime in San Francisco is below average for large cities. In 2019 and 2020, San Francisco ranked in the bottom half among major U.S. cities, with rates of 670 and 540 violent crime incidents per 100,000 residents, respectively. Hence, we are interested in how Robbery had increased the violent crime level in San Francisco.
2 Data Anlysis: Robberies in San Francisco
From January 2003 to December 2012, there were 35817 incidents of robbery in San Francisco reported to the police, while there were 32786 incidents of robbery reported from 2013 to 2022 (Data source).
As an overview, the robbery rate has decreased by 8.5% since the decade of 2003 to the last decade, however the number is not indicating a significantly decrease, which reflects the robbery is still a key factor that affect the level of crimes in San Francisco.
2.1 Timeseries: How the occurrence of Robbery changed over the time?
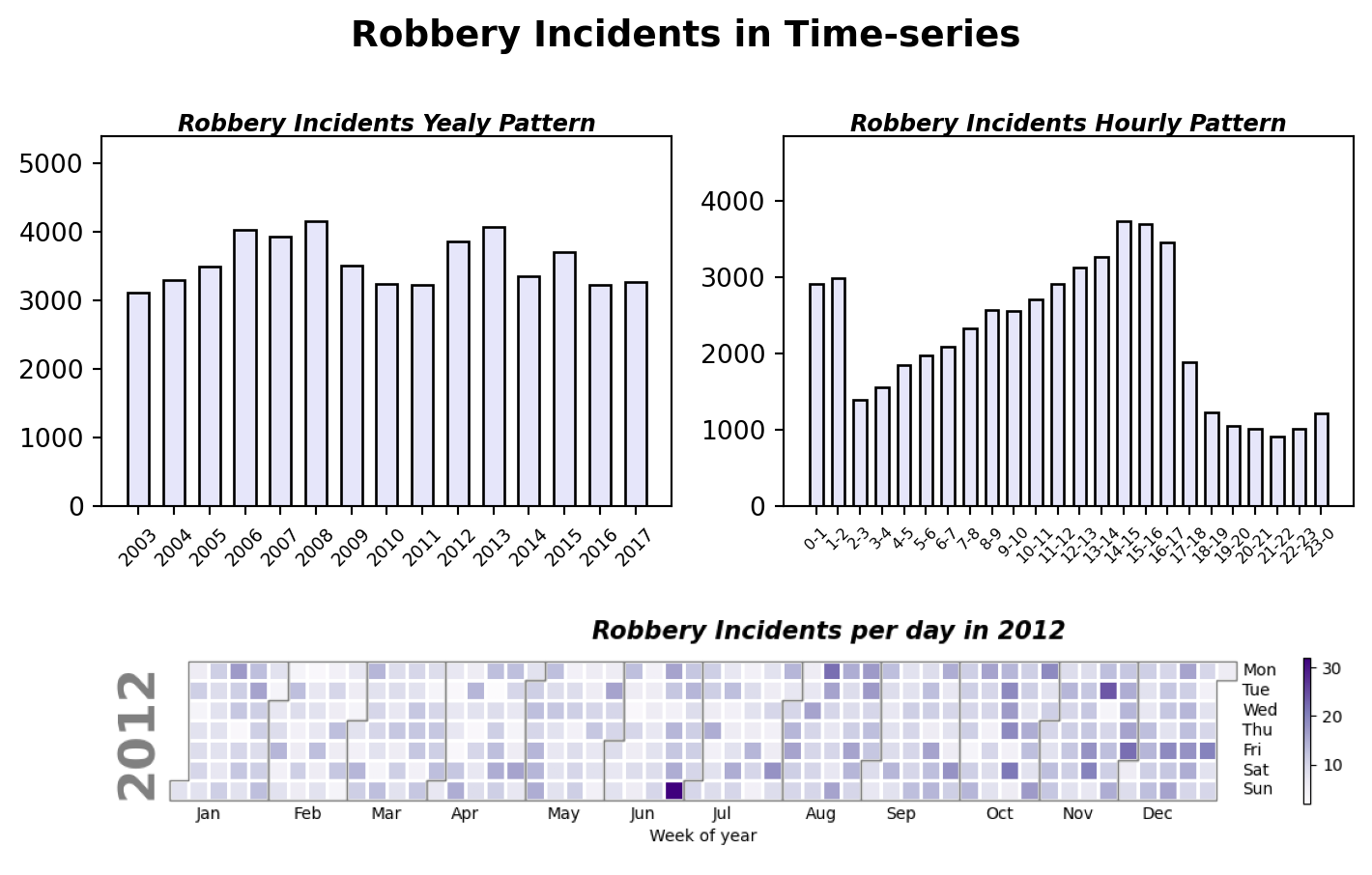
If we divide the time of the incidents into hourly timeslots, it becomes apparent that the number of robberies reaches its highest point between 2 and 3 pm and remains consistently high until 5 pm. After 5 pm, there is a sharp decline during the evening, but a secondary peak occurs between 1 and 2 am.Between 2 am and 2 pm, the number of incidents increases steadily.
From 2003 to 2017, we can see the incidents fluctuated accross years. Specifically, in 2010 and 2011, it has a significant decreased from 2008 and 2009. The Rand Corporation studied this phenomenon on a national level in 2010, concluding that the crime prevention benefit of hiring more officers is well worth the cost. Reference
However, there was a resurgence in incidents in 2012, with a noticeable gap from the previous year. After analyzing the robbery incidents data in 2012, we observed a marked increase in robberies on the final Sunday in June in San Francisco.
Further investigation revealed that this date coincided with the San Francisco LGBT Pride Parade, which started at Beale Street and Market Street and continued down to 8th Street.
2.2 Map: Where does robbery most likely take place?
Let’s examine the robbery locations on June 24, 2012, during the Pride Parade in San Francisco which typically occurs on Market Street(Reference: Wikipedia).
In the visualization of the robbery incidents data on the day when the Pride Parade occured, the three location marks Market Street, 8th Street and Beala Street respectively. The red dots indicates the location of the robberies taking place. It shows an obvious fact that in the 33 incidents recorded on 24 June 2012, most of the crimes happened in the range of the routes that the parade covered.
Make this Notebook Trusted to load map: File -> Trust Notebook
The incidence of robbery is relatively high in the near Market Street, indicating that criminals are more prone to commit robbery in crowded areas, thus increasing their chances of escape. Additionally, the buildings and blocks in the Market Street area are more densely packed, offering additional cover and refuge for criminals.
This observation also aligns with the result of the heatmap regarding robbery occurrence in 2011 and 2012, as the map above indicates. It reveals the fact that areas with a high concentration of stores and a large population, along with a complex urban infrastructure, are more susceptible to robbery incidents.
However, despite the fact that the Tenderloin district where Market Street located had the highest number of robbery incidents, the data implies that it was not the most active police district. This fact can be counted to the assumption that there was a lack of police power resources in Tenderloin district.
2.3 Interactive Visualization: Police district performance
How does the police perform in the different districts?
As the activities of police can be a key factor that effect on the crime rates, we therefore would like to see how the number of crimes has changed based on different districts. The data are used and maintained by the Police Department, which indicates that the number of records reflects the activities of the police districts. The incidents that are not reported and recorded is excluded to the scope of our discussion.
We normalized the occurrences of crime incidents and then created an interactive visualization to enable easy inspection of the normalized number of incidents in each police district.
Through the interactive visualization, users are able to select the district they are interested in to observe the data. From the visualization, we can first get the information that each police district has the similar pattern of activities: almost all districts has the relatively high frequency of criminals during 7 am to 23 pm, with the peak at 11 am. It can be reflected that there are more active police resources working during day shift.
However the normalized occurrence of crimes has decreased by half during 0 am to 7 am, and the bottom occurs at the timeslot of 4 am to 5 am. In general, Park District, Taravel District and Southern District were likely to have the best performance due to the relatively larger amount of crime records. Police in Tenderloin District has better performance than Central District at the timeslots of 4-7 am and 12-16 pm, however, however it was less performed than Central District from 17 pm to 3 am.
However, by inspecting in the data of the total occurrence of all categories of crimes, we were not able to catch an apparent correlation between the pattern of crimes and the activity of police districts.
3 Conclusion
In summary, we conducted an analysis of robbery incidents in San Francisco from 2008 to 2012 using time series analysis.
Our investigation revealed that robbery incidents generally peak during the summer months, as indicated by the calendar plots spanning 2003 to 2017.
We also found that the busiest city center is more prone to crime. However, we did not observe a positive correlation between police activities in each district and the number of robbery incidents.